Tools · Hacker News ·
Real-time LLM Inference on Standard GPUs: 3k tokens/s per request
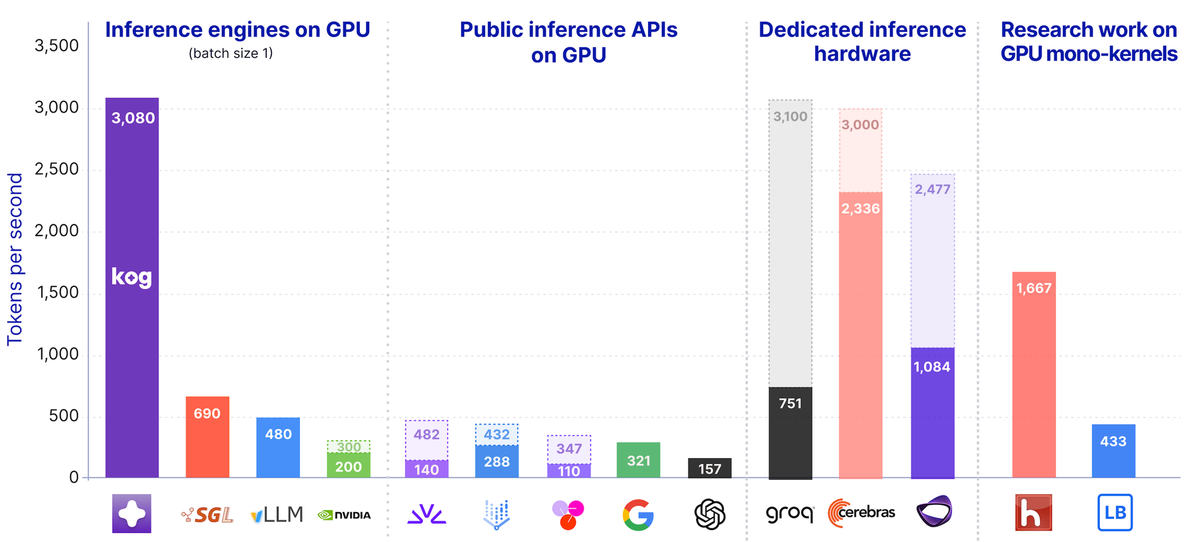
Kog.ai reports achieving 3,000 tokens per second per request for real-time LLM inference on standard GPUs.
Tools · Hacker News ·
Kog.ai reports achieving 3,000 tokens per second per request for real-time LLM inference on standard GPUs.