Models · MarkTechPost ·
Miso Labs Releases MisoTTS: An 8B Emotive Text-to-Speech Model with Open Weights
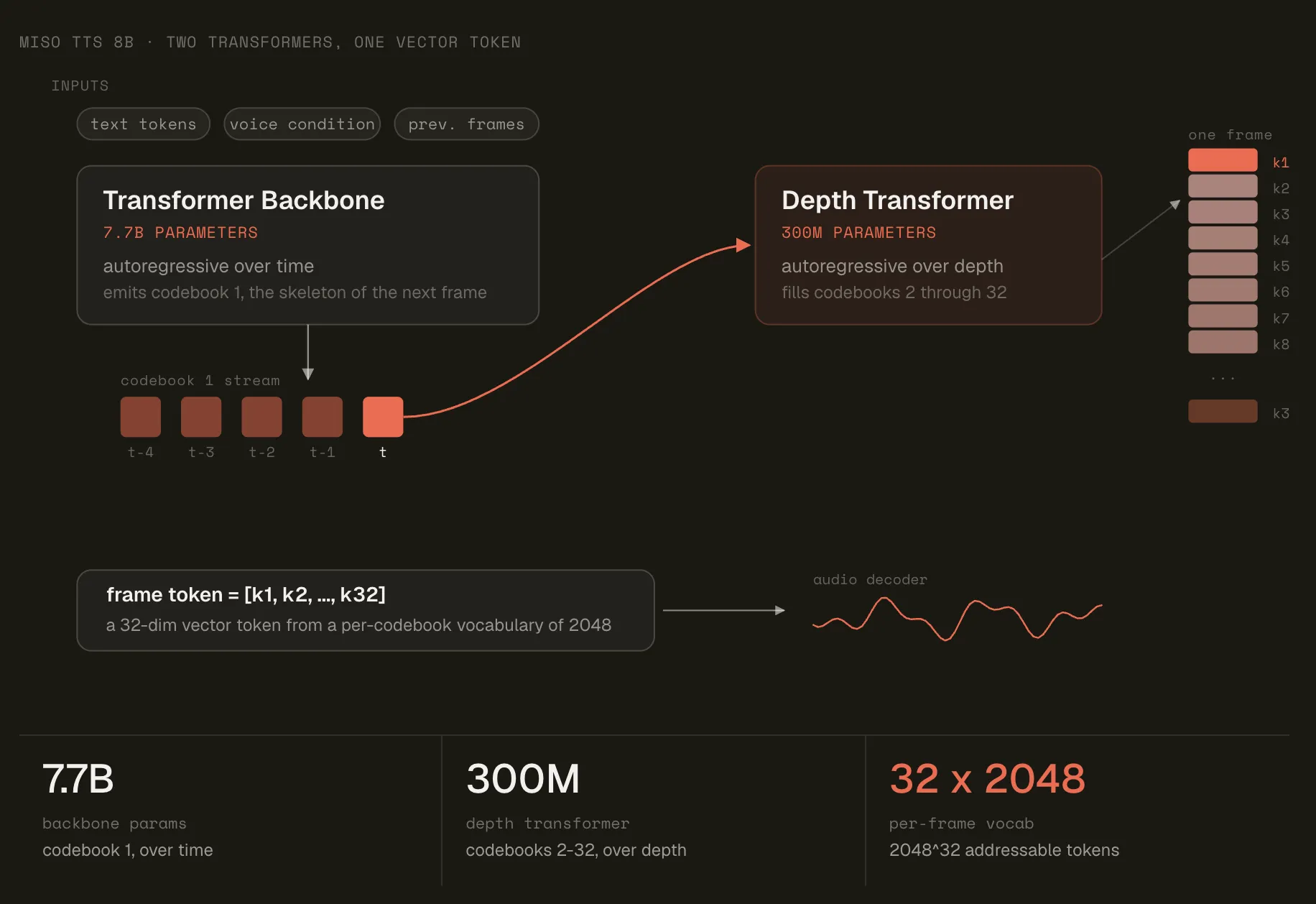
Miso Labs released MisoTTS, an open-weights 8B text-to-speech model. The system uses residual vector quantization to expand sonic range and conditions on text plus audio context to match speaker tone, with a 7.7B backbone and 300M depth decoder.