Research · MarkTechPost ·
MEMO: A Modular Framework for Training a Dedicated Memory Model on New Knowledge Without Modifying LLM Parameters
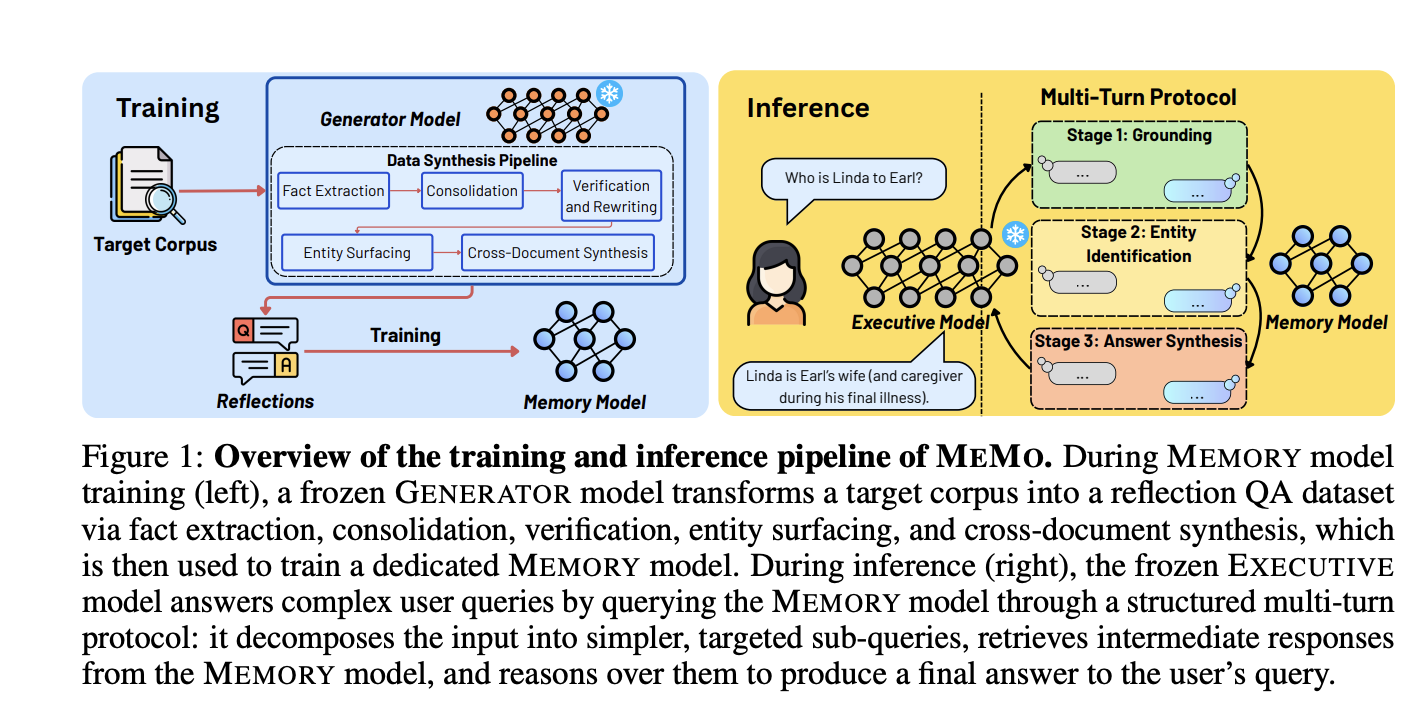
Researchers from NUS, MIT, and A*STAR introduced MEMO, a modular framework that stores corpus knowledge in a separate trainable memory model instead of changing LLM parameters. The approach is designed to add new knowledge without retraining the base language model.