Models · Hacker News ·
Liquid AI reveals 8B-A1B MoE trained on 38T
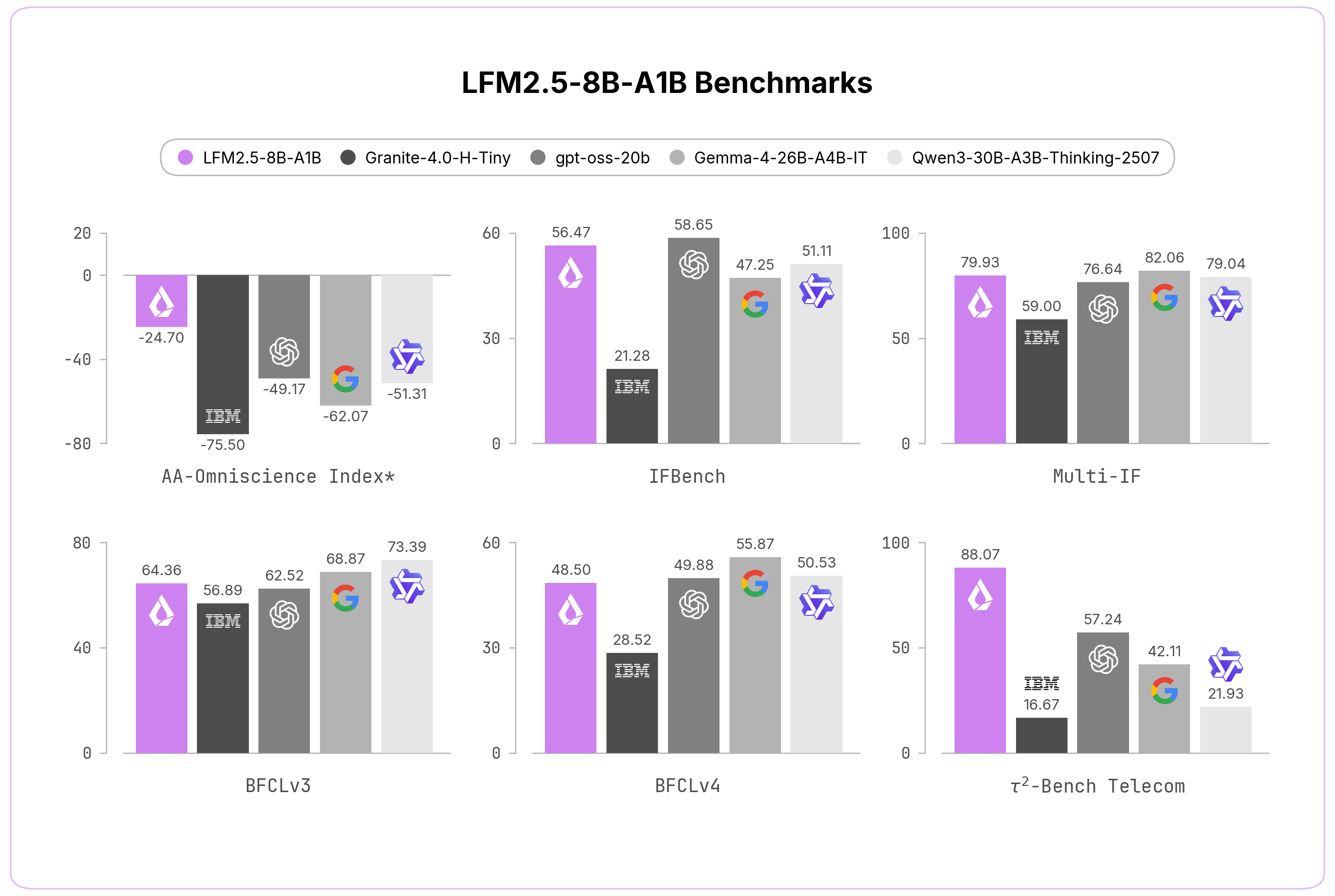
Liquid AI has released LFM2 5, an 8B parameter Mixture-of-Experts model with 1B active parameters, trained on 38 trillion tokens. The model aims to improve efficiency and performance for large-scale AI applications.