Tools · AWS ML Blog ·
Introducing container caching in Amazon SageMaker AI for faster model scaling
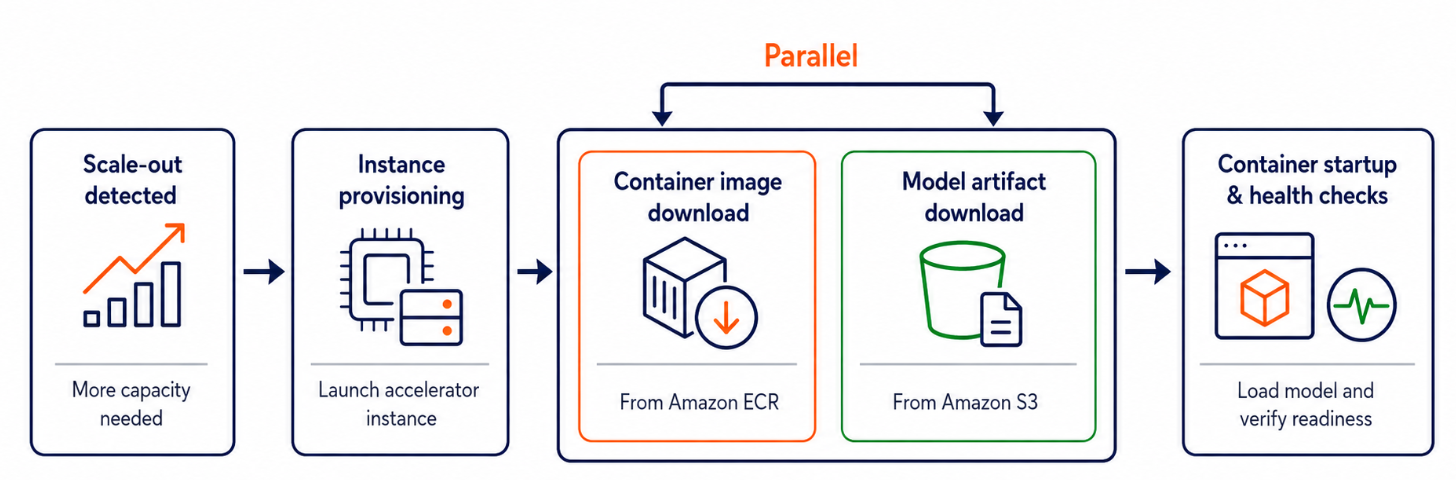
AWS announced container image caching for Amazon SageMaker AI inference to reduce scale-out latency. The company says the feature can cut end-to-end latency by up to 2x for generative AI models during scaling events.