Tools · AWS ML Blog ·
Accelerate LLM model loading and increase context windows with GPUDirect on Amazon FSx for Lustre and TurboQuant
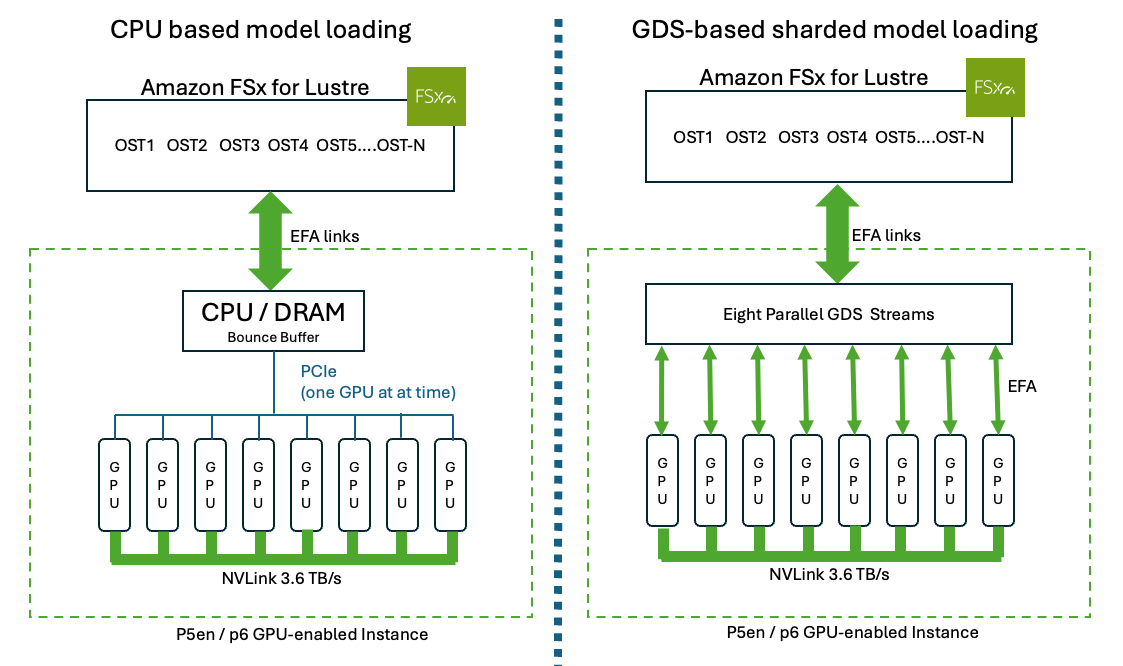
AWS introduces GPUDirect on Amazon FSx for Lustre with TurboQuant to accelerate LLM model loading and increase context windows. The integration aims to reduce wait times for GPU inference by optimizing data transfer to High Bandwidth Memory.